Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
coherence has several key features that makes big worlds viable. Read more about:
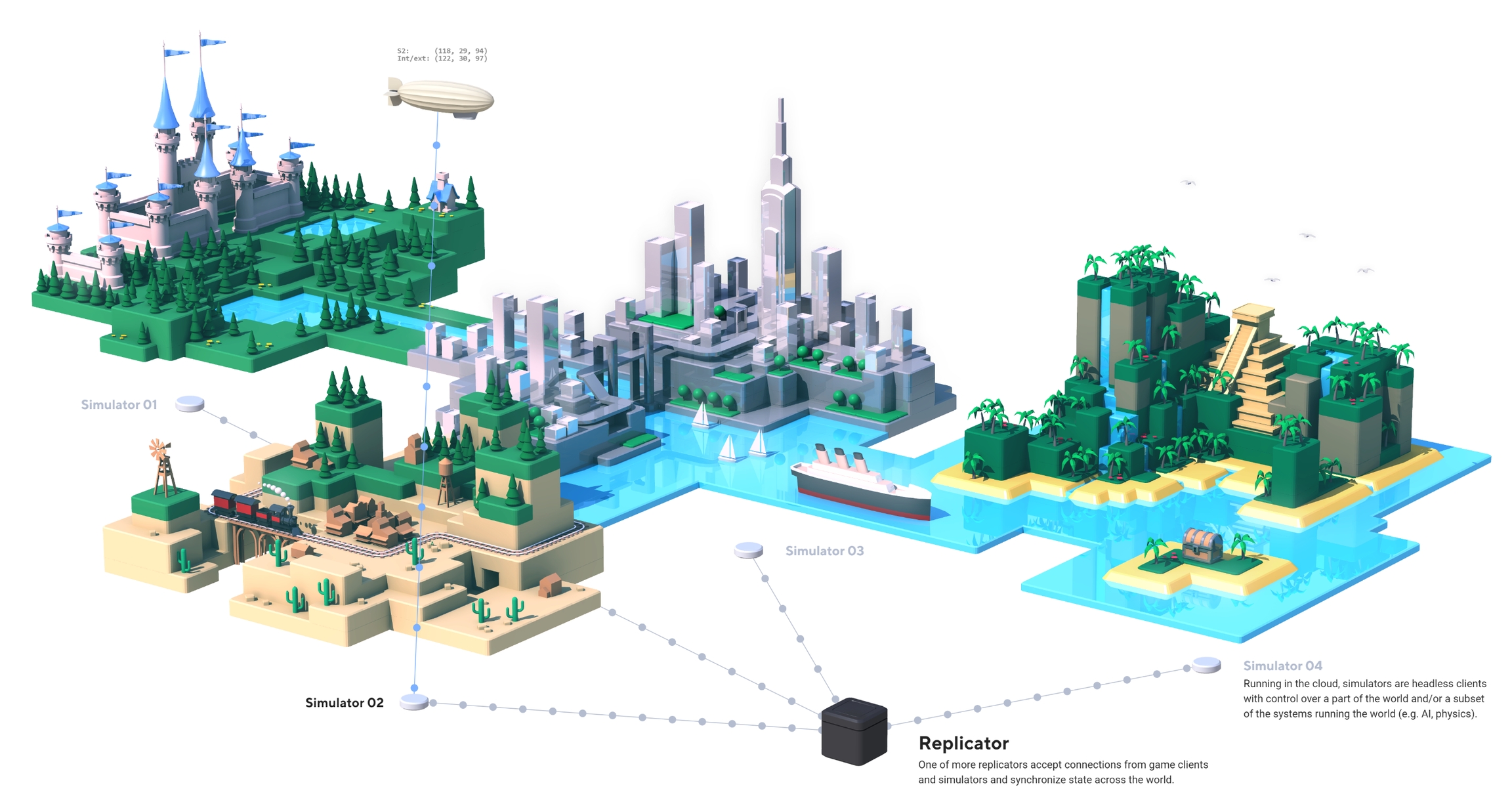
coherence allows us to use multiple Simulators to split up a large game world with many entities between them. This is called spatial load balancing.
You can see load balancing in action in this video:
While load balancing is supported for standalone projects, our cloud services currently only support associating one Simulator to a Room or World. This will be extended in the near future. Enterprise customers can still run multiple Simulators in their own cloud environment.
If you're using a VCS (which we highly recommend you to) like git, Subversion or PlasticSCM, here's a few tips.
You can ignore (as in, not version) Assets/coherence/baked and its .meta file in most cases, but it's completely safe to include them too. If you decide to ignore them, every other fresh copy of the project (including continuous integration setups) has to Bake for such files to be generated.
If your build pipeline relies on asset checksums for verification, you should version the forementioned files.
Make sure Assets/coherence/Gathered.schema is treated as a binary and not as a text file (where conflicts can be auto-resolved via content diffs). The Gathered.schema, although a text file, is meant to be thought of as a binary file.
Each VCS has different mechanisms to work around this. Read the documentation of your VCS of choice to learn how to set this up.
When using git, you can add this line to your .gitattributes file (or create one in the root of your repo, if it doesn't exist)
To learn more about how gitattributes works, refer to their documentation.
The simulation frame represents an internal clock that every Client syncs with a Replication Server. This clock runs at a 60Hz frequency which means that the resolution of a single simulation frame is ~16ms.
There are 3 different simulation frame types used within the coherence:
Accessible via CoherenceBridge.NetworkTime.
Every Client tries to match the Client simulation frame with the Server simulation frame by continuously monitoring the distance between the two and adjusting the NetworkTime.NetworkTimeScale based on the distance, ping, delta time, and several other factors starting from the first simulation frame captured when the client first connects in NetworkTime.ConnectionSimulationFrame
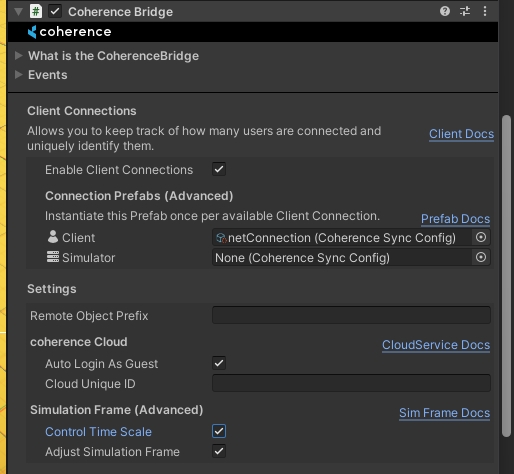
Unity's Time.timeScale is automatically set to the value of NetworkTime.NetworkTimeScale if the CoherenceBridge.controlTimeScale is set to true (default value).
In perfect conditions, all Clients connected to a single session should have exactly the same ClientSimulationFrame value at any point in the real-world time.
The value of the ClientSimulationFrame can jump by more than 1 between two engine frames if the frame rate is low enough.
The Client simulation frame is used to timestamp any outgoing Entity changes to achieve a consistent view of the World for all players. The receiving side uses it for interpolation of the synced values.
Local simulation frame that progresses in user-controlled fixed steps. Accessible via CoherenceBridge.ClientFixedSimulationFrame.
By default, the fixed step value is set to the Time.fixedDeltaTime.
Just like the basic Client simulation frame, it uses the NetworkTime.NetworkTimeScale to correct the drift. The fixed simulation frame is used as a base for the fixed-step, network-driven simulation loop that is run via CoherenceBridge.OnFixedNetworkUpdate. This loop is used internally to power the CoherenceInput and the GGPO code.
Unlike ClientSimulationFrame, the CoherenceBridge.OnFixedNetworkUpdate loop never skips frames - it is guaranteed to run for every single frame increment.
coherence Input Queues are backed by a rolling buffer of inputs transmitted between the Clients. This buffer can be used to build a fully deterministic simulation with a client side-prediction, rollback, and input delay. This game networking model is often called the GGPO (Good Game Peace Out).
Input delay allows for a smooth, synchronized netplay with almost no negative effect on the user experience. The way it works is input is scheduled to be processed X frames in the future. Consider a fighting game scenario with two players. At frame 10 Player A presses a kick button that is scheduled to be executed at frame 13. This input is immediately sent to Player B. With a decent internet connection, there's a very good chance that Player B will receive that input even before his frame 13. Thanks to this, the simulation is always in sync and can progress steadily.
Prediction is used to run the simulation forward even in the absence of inputs from other players. Consider the scenario from the previous paragraph - what if Player B doesn't receive the input on time? The answer is very simple - we just assume that the input state hasn't changed and progress with the simulation. As it turns out this assumption is valid most of the time.
Rollback is used to correct the simulation when our predictions turn out wrong. The game keeps historical states of the game for past frames. When an input is received for a past simulation frame the system checks whether it matches the input prediction made at that frame. If it does we don't have to do anything (the simulation is correct up to that point). If it doesn't match, however, we need to restore the simulation state to the last known valid state (last frame which was processed with non-predicted inputs). After restoring the state we re-simulate all frames up to the current one, using the fresh inputs.
GGPO is not recommended for FPS-style games. The correct rollback networking solution for those is planned to be added in the future.
In a deterministic simulation, given the same set of inputs and a state we are guaranteed to receive the same output. In other words, the simulation is always predictable. Deterministic simulation is a key part of the GGPO model, as well as a lockstep model because it lets us run exactly the same simulation on multiple Clients without a need for synchronizing big and complex states.
Implementing a deterministic simulation is a non-trivial task. Even the smallest divergence in simulation can lead to a completely different game outcome. This is usually called a desync. Here's a list of common determinism pitfalls that have to be avoided:
Using Update to run the simulation (every player might run at a different frame rate)
Using coroutines, asynchronous code, or system time in a way that affects the simulation (anything time-sensitive is almost guaranteed to be non-deterministic)
Using Unity physics (it is non-deterministic)
Using random numbers generator without prior seed synchronization
Non-symmetrical processing (e.g. processing players by their spawn order which might be different for everyone)
Relying on floating point numbers across different platforms, compilations or processor types
We'll create a simple, deterministic simulation using provided utility components.
This is the recommended way of using Input Queues since it greatly reduces the implementation complexity and should be sufficient for most projects.
If you'd prefer to have full control over the input code feel free to use theCoherenceInput and InputBuffer directly.
Our simulation will synchronize the movement of multiple Clients, using the rollback and prediction in order to cover for the latency.
Start by creating a Player component and a Prefab for it. We'll use the client connection system to make our Player represent a session participant and automatically spawn the selected Prefab for each player that connects to the Server. The Player will also be responsible for handling inputs using the CoherenceInput component.
Create a Prefab from cube, sphere, or capsule, so it will be visible on the scene. That way it will be easier to verify visually if the simulation works, later.
When building an input-based simulation it is important to use the Client connection system, that is not a subject to the LiveQuery. Objects that might disappear or change based on the client-to-client distance are likely to cause simulation divergence leading to a desync.
Our Player code looks as follows:
GetMovement and SetMovement will be called by our "central" simulation code. Now that we have our Player class written, let's prepare a Prefab for it.
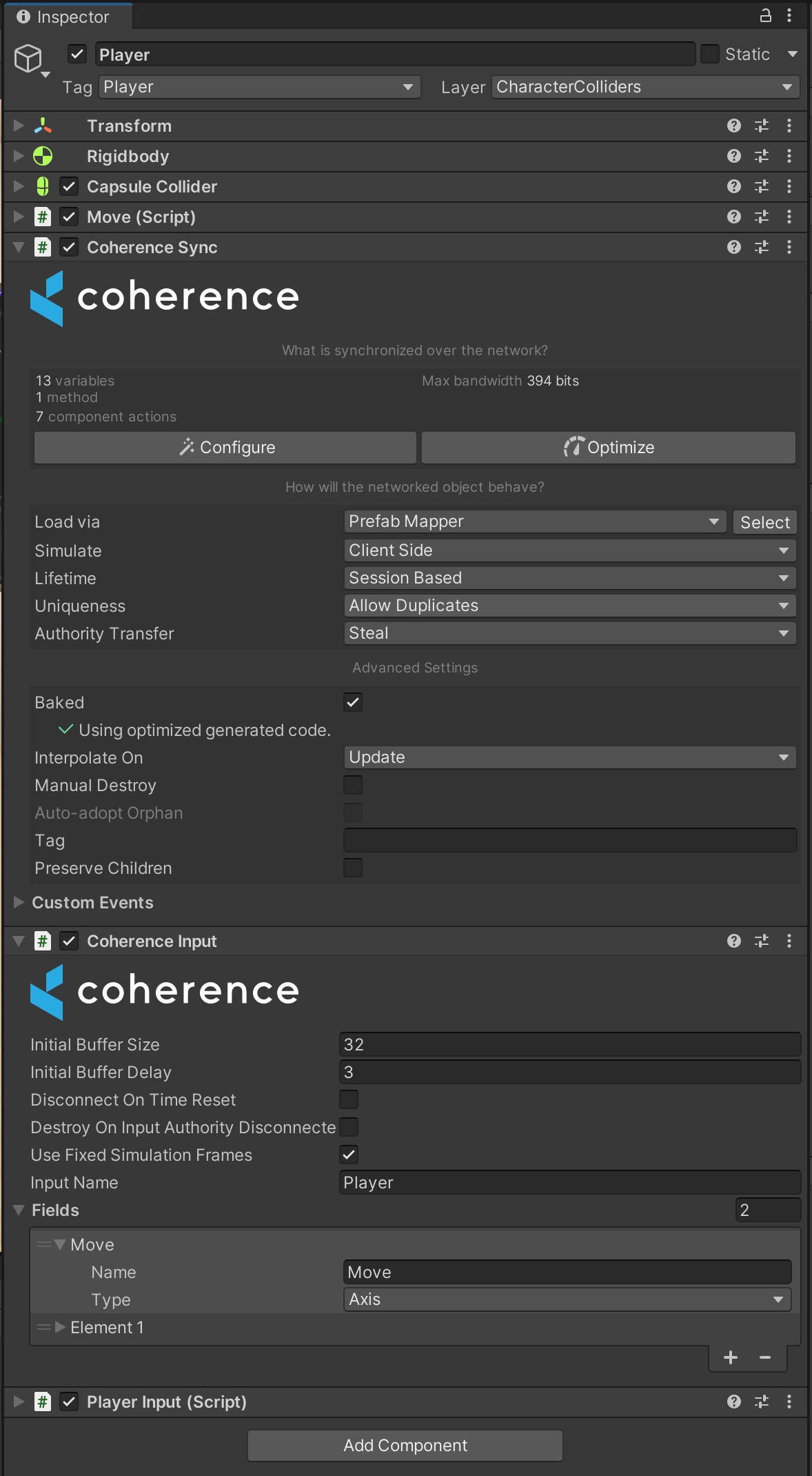
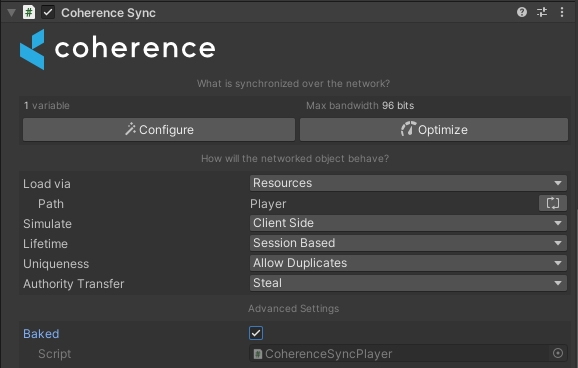
Create a GameObject and attach the Player script to it, using the CoherenceSync inspector create a Prefab.
The inspector view for our Prefab should look as follows:
A couple of things to note:
A Move 2D axis has been added to the CoherenceInput which will let us sync the movement input state.
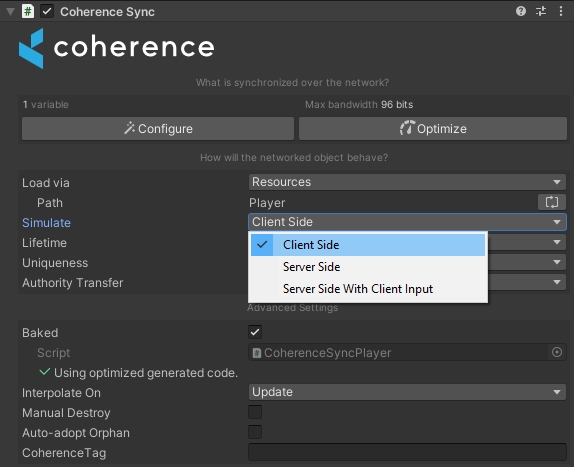
Unlike in the Server authoritative setup our simulation uses client-to-client communication, meaning each Client is responsible for its Entity and sending inputs to other Clients. To ensure this behavior set the Simulate property to Client Side.
In a deterministic simulation, it is our code that is responsible for producing deterministic output on all Clients. This means that automatic syncing is no longer desirable. To turn auto-syncing off, click on the button with the coherence symbol next to bindings in the Configuration window and select Always Client Predict. This will stop the automatic syncing, and allow us to predict this binding and write to it.
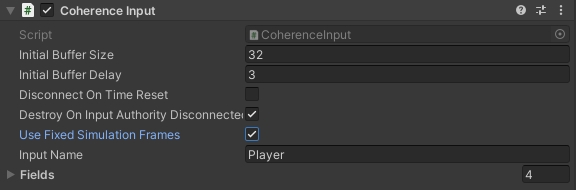
In order for inputs to be processed in a deterministic way, we need to use fixed simulation frames. Check the CoherenceInput > Use Fixed Simulation Frames checkbox.
Make sure to use baked mode (CoherenceInput > Use Baked Script) - inputs do not work in reflection mode.
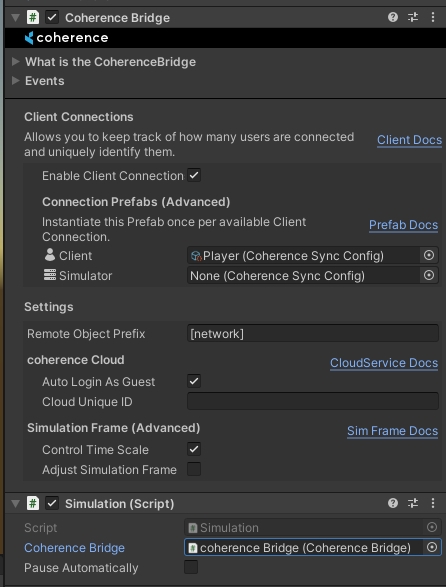
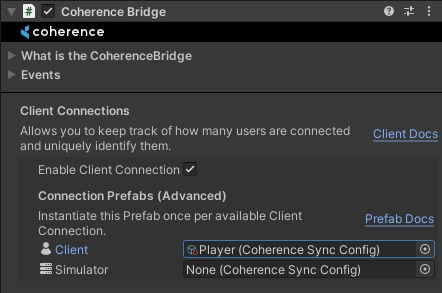
Since our player is intended to be a Client Connection Prefab, we must set it as such in the CoherenceBridge and Enable Client Connections:
Before we move on to the simulation, we need to define our simulation state which is a key part of the rollback system. The simulation state should contain all the information required to "rewind" the simulation in time. For example, in a fighting game that would be the position of all players, their health, and perhaps a combo gauge level. In a shooting game, this could be player positions, their health, ammo, and map objective progression.
In the example we're building, player position is the only state. We need to store it for every player:
The state above assumes the same number and order of players in the simulation. The order is guaranteed by the CoherenceInputSimulation, however, handling a variable number of Clients is up to the developer.
Simulation code is where all the logic should happen, including applying inputs and moving our Players:
We have identified a misprediction bug in coherence 1.1.3 and earlier versions that causes a failed rollback right after a new Client joins a session, throwing relevant error messages. However if the Client manages to connect, this won't affect the rest of the simulation. The fix should ship in the next release.
SetInputs is called by the system when it's time for our local Player to update its input state using the CoherenceInput.
Simulate is called when it's time to simulate a given frame. It is also called during frame re-simulation after misprediction - don't worry though, the complex part is handled by the CoherenceInputSimulation internals - all you need to do in this method is apply inputs from the CoherenceInput to run the simulation.
Rollback is where we need to set the simulation state back to how it was at a given frame. The state is already provided in the state parameter, we just need to apply it.
CreateState is where we create a snapshot of our simulation so it can be used later in case of rollback.
OnClientJoined and OnClientLeft are optional callbacks. We use them here to start and stop the simulation depending on the number of Clients.
The SimulationEnabled is set to "false" by default. That's because in a real-world scenario the simulation should start only after all Clients have agreed for it to start, on a specific frame chosen, for example, by the host.
Starting the simulation on a different frame for each Client is likely to cause a desync (as well as joining in the middle of the session, without prior simulation state synchronization). Simulation start synchronization is however out of the scope of this guide so in our simplified example we just assume that Clients don't start moving immediately after joining.
As a final step, attach the Simulation script to the Bridge object on scene and link the Bridge back to the Simulation:
That's it! Once you build a client executable you can verify that the simulation works by connecting two Clients to the Replication Server. Move one of the Clients using arrow keys while observing the movement being synced on the other one.
Due to the FixedNetworkUpdate running at different (usually lower) rate than Unity's Update loop, polling inputs using the functions like Input.GetKeyDown is susceptible to a input loss, i.e. keys that were pressed during the Update loop might not show up as pressed in the FixedNetworkUpdate.
To illustrate why this happens consider the following scenario: given that Update is running five times for each network FixedNetworkUpdate, if we polled inputs from the FixedNetworkUpdate there's a chance that an input was fully processed within the five Updates in-between FixedNetworkUpdates, i.e. a key was "down" on the first Update, "pressed" on the second, and "up" on a third one.
To prevent this issue from occurring you can use the FixedUpdateInput class:
The FixedUpdateInput works by sampling inputs at Update and prolonging their lifetime to the network FixedNetworkUpdate so they can be processed correctly there. For our last example that would mean "down" & "pressed" registered in the first FixedNetworkUpdate after the initial five updates, followed by an "up" state in the subsequent FixedNetworkUpdate.
The example above works only with the legacy input system (UnityEngine.Input).
There's a limit to how many frames can be predicted by the Clients. This limit is controlled by the CoherenceInput.InputBufferSize. When Clients try to predict too many frames into the future (more frames than the size of the buffer) the simulation will issue a pause. This pause affects only the local Client. As soon as the Client receives enough inputs to run another frame the simulation will resume.
To get notified about the pause use the OnPauseChange(bool isPaused) method from the CoherenceInputSimulation:
This can be used for example to display a pause screen that informs the player about a bad internet connection.
To recover from the time gap created by the pause the Client will automatically speed up the simulation. The time scale change is gradual and in the case of a small frame gap, can be unnoticeable. If a manual control over the timescale is desired set the CoherenceBridge.controlTimeScale flag to "false".
The CoherenceInputSimulation has a built-in debugging utility that collects various information about the input simulation on each frame. This data can prove extremely helpful in finding a simulation desync point.
The CoherenceInputDebugger can be used outside the CoherenceInputSimulation. It does however require the CoherenceInputManager which can be retrieved through the CoherenceBridge.InputManager property.
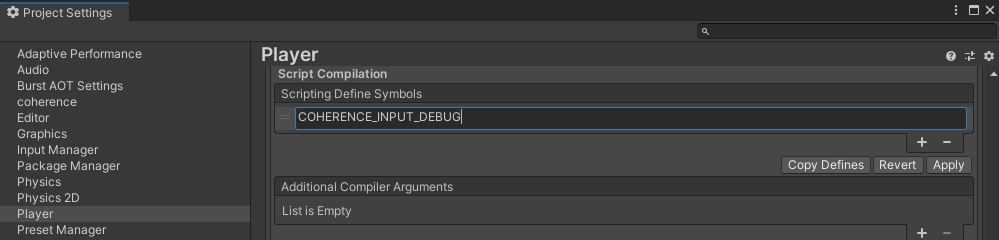
Since debugging might induce a non-negligible overhead it is turned off by default. To turn it on, add a COHERENCE_INPUT_DEBUG scripting define:
From that point, all the debugging information will be gathered. The debug data is dumped to a JSON file as soon as the Client disconnects. The file can be located under a root directory of the executable (in case of Unity Editor the project root directory) under the following name: inputDbg_<ClientId>.json, where <ClientId> is the CoherenceClientConnection.ClientId of the local client.
Data handling behavior can be overridden by setting the CoherenceInputDebugger.OnDump delegate, where the string parameter is a JSON dump of the data.
The debugger is available as a property in the simulation base class: CoherenceInputSimulation.Debugger. Most of the debugging data is recorded automatically, however, the user is free to append any arbitrary information to a frame debug data, as long as it is JSON serializable. This is done by using the CoherenceInputDebugger.AddEvent method:
Since the simulation can span an indefinite amount of frames it might be wise to limit the number of debug frames kept by the debugging tool (it's unlimited by default). To do this use the CoherenceInputDebugger.FramesToKeep property. For example, setting it to 1000 will instruct the debugger to keep only the latest 1000 frames worth of debugging information in the memory.
Since the debugging tool uses JSON as a serialization format, any data that is part of the debug dump must be JSON-serializable. An example of this is the simulation state. The simulation state from the quickstart example is not JSON serializable by default, due to Unity's Vector3 that doesn't serialize well out of the box. To fix this we need to give JSON serializer a hint:
With the JsonProperty attribute, we can control how a given field/property/class will be serialized. In this case, we've instructed the JSON serializer to use the custom UnityVector3Converter for serializing the vectors.
You can write your own JSON converters using the example found here. For information on the Newtonsoft JSON library that we use for serialization check here.
To find a problem in the simulation, we can compare the debug dumps from multiple clients. The easiest way to find a divergence point is to search for a frame where the hash differs for one or more of the clients. From there, one can inspect the inputs and simulation states from previous frames to find the source of the problem.
Here's the debug data dump example for one frame:
Explanation of the fields:
Frame - frame of this debug data
AckFrame - the common acknowledged frame, i.e. the lowest frame for which inputs from all clients have been received and are known to be valid (not mispredicted)
ReceiveFrame - the common received frame, i.e. the lowest frame for which inputs from all clients have been received
AckedAt - a frame at which this frame has been acknowledged, i.e. set as known to be valid (not mispredicted)
MispredictionFrame - a frame that is known to be mispredicted, or -1 if there's no misprediction
Hash - hash of the simulation state. Available only if the simulation state implements the IHashable interface
Initial state - the original simulation state at this frame, i.e. a one before rollback and resimulation
Initial inputs - original inputs at this frame, i.e. ones that were used for the first simulation of this frame
Updated state - the state of the simulation after rollback and resimulation. Available only in case of rollback and resimulation
Updated inputs - inputs after being corrected (post misprediction). Available only in case of rollback and resimulation
Input buffer states - dump of the input buffer states for each client. For details on the fields see the InputBuffer code documentation
Events - all debug events registered in this frame
There are two main variables which affect the behaviour of the InputBuffer:
Initial buffer size - the size of the buffer determines how far into the future the input system is allowed to predict. The bigger the size, the more frames can be predicted without running into a pause. Note that the further we predict, the more unexpected the rollback can be for the player. The InitialBufferSize value can be set directly in code however it must be done before the Awake of the baked component, which might require a script execution order configuration.
Initial buffer delay - dictates how many frames must pass before applying an input. In other words, it defines how "laggy" the input is. The higher the value, the less likely Clients are going to run into prediction (because a "future" input is sent to other Clients), but the more unresponsive the game might feel. This value can be changed freely at runtime, even during a simulation (it is however not recommended due to inconsistent input feeling).
The other two options are:
Disconnect on time reset - if set to "true" the input system will automatically issue a disconnect on an attempt to resync time with the Server. This happens when the Client's connection was so unstable that frame-wise it drifted too far away from the Server. In order to recover from that situation, the Client performs an immediate "jump" to what it thinks is the actual server frame. There's no easy way to recover from such a "jump" in the deterministic simulation code, so the advised action is to simply disconnect.
Use fixed simulation frames - if set to "true" the input system will use the IClient.ClientFixedSimulationFrame frame for simulation - otherwise the IClient.ClientSimulationFrame is used. Setting this to "true" is recommended for a deterministic simulation.
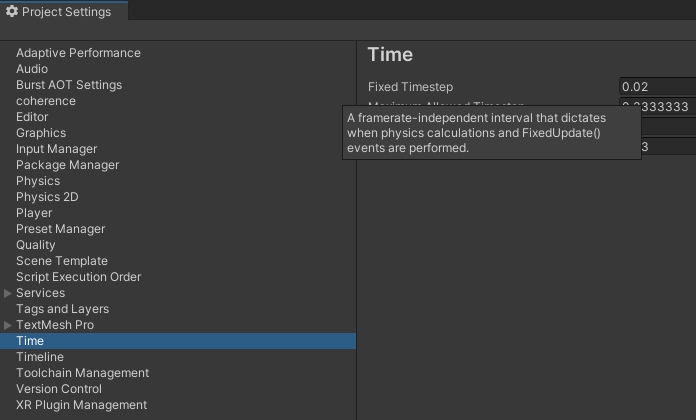
The fixed network update rate is based on the Fixed Timestep configured through the Unity project settings:
To know the exact fixed frame number that is executing at any given moment use the IClient.ClientFixedSimulationFrame or CoherenceInputSimulation.CurrentSimulationFrame property.
Command-line interface tools explained
Found in <package-root>/.Runtime/<platform>/.
replication-server --help serve
To start the Server, you need to give it the location of the schema.
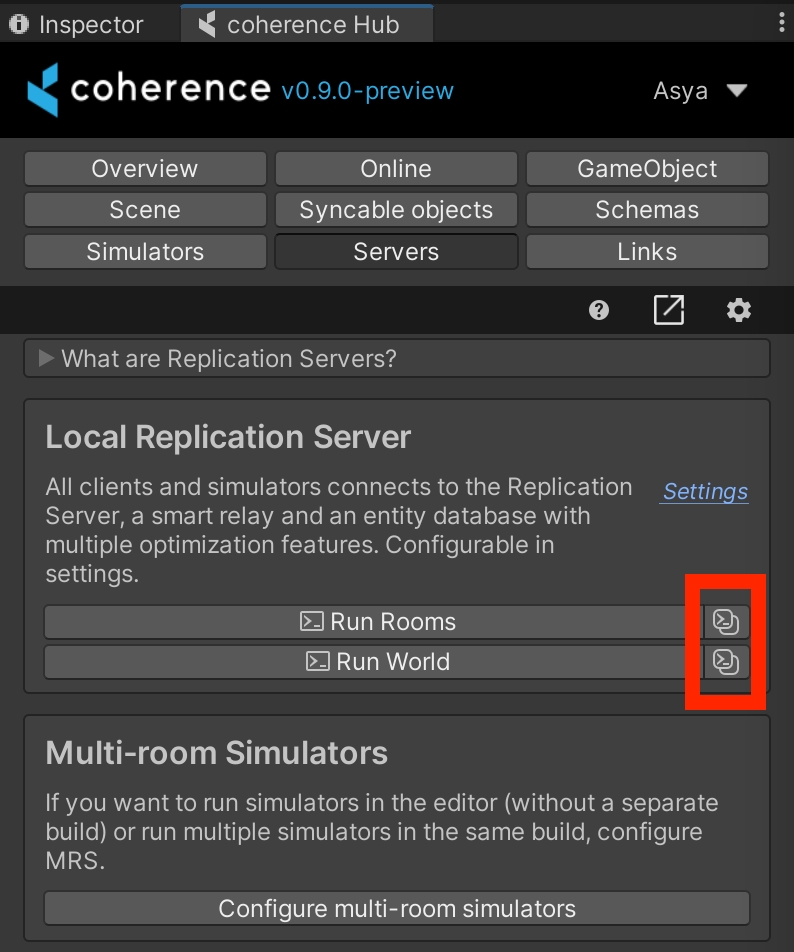
You can copy the CLI commands to start the replication server form coherence Hub > Servers tab_._
You can also define other parameters like min-query-distance (the minimum distance the LiveQuery needs to move for the Replicator to recognize a change), send and receive frequency, ip and port number.
Minimal parameters set is presented in the example below:
replication-server serve --port 32001 --signalling-port 32002 --send-frequency 20 --recv-frequency 60 --web-support --env dev --schema "/Users/coherence/unity/Coherence.Toolkit/Toolkit.schema,/Users/coherence/MyProject/Library/coherence/Gathered.schema"
replication-server --help listen
These are the primitive types supported in a coherence schema:
Uses a default range of -2147483648 to 2147483647 (32 bits).
Uses the default range of 0 to 4294967295 (32 bits).
Uses the default range of -9223372036854775808 to 9223372036854775807 (64 bits).
Uses the default range of 0 to 18446744073709551615 (64 bits).
Encoded using one of the following compression types: None, Truncated, FixedPoint (defaults to None).
Higher precision floating point using 64 bits. It does not support compression.
Encoded using a single bit.
Encoded using two floats with a specified compression (defaults to None).
Encoded using three floats with a specified compression (defaults to None).
Encoded using three components and a sign bit.
Encoded using four components (RGBA).
A string with up to 63 bytes encoded using 6 bits for length.
An array of bytes with an upper limit of 511 bytes encoded using 9 bits for length.
Packet fragmentation is not supported yet in this version, so packets bigger than the internal MTU (~1200 bytes) may be never sent.
The Entity type is used to keep references to other Entities. Technically the reference is stored as a local index that has to be resolved to an actual Entity before usage. Also, since a Client might not know about the referenced Entity (due to it being outside of its LiveQuery) an Entity reference might be impossible to resolve in some circumstances. Your Client code will have to take this into account and be programmed in a defensive way that handles missing Entities gracefully.
The most common definition in schemas is components, which correspond to replicated fields for baked MonoBehaviours.
The definition takes a name of the component, and on the following lines an indented list of member variables, each one followed by their primitive type (see above.) The indentation has to be exactly 2 spaces. Here's how it might look:
After code generation, this will give access to a component with the name Portal that has the members locked, connectedTo, and size.
Optionally, each member/type pair can have additional meta data listed on the same line, using the following syntax:
This is how it might look in an actual example:
There are some components that are built into the Protocol Code Generator and that you will always have access to.
Commands are defined very similarly to components, but they use the command keyword instead.
Here's a simple example of a command:
Routing defines to whom the command can be sent. Currently, two values are supported:
AuthorityOnly - command will be received only by the owner of the target Entity
All - command will be received by every Client that has a copy of this Entity
Inputs represent a group of values that are snapshotted every frame (or fixed frame). This snapshot is then sent to other clients or a session host, so it can be processed by the same code on both ends, resulting in the same outcome.
Example of an input:
Schemas have limits to protect the Replication Server. Ensure you stay within these limits:
A single schema cannot have more than 10 million characters
A component/command name cannot be more than 512 characters
A field/archetype/input/enum name cannot be longer than 128 characters
A component cannot have more than 128 fields
Tips and trips for setting up Continuous Integration (CI) for your projects
Continuous Integration means that any changes to the project are merged frequently into the main branch, and automation (especially of testing) is used to ensure quality. The main benefits of Continuous Integration (henceforth CI) are that it makes software development easier, faster, and less risky for developers. Building your Game Client with CI and automated testing might require coherence setup.
For automated delivery of your project changes and testing it in CI, you can take the following steps to make sure coherence is set up appropriately in your project before building a standalone Client.
Make sure you generate your schema or schemas before building. For example, you can create a build method and call it from Unity via command line as a custom method.
After that, you will need to bake your code according to the schema. Baking is also accessible via the Unity command line in a custom method.
To start the Replication Server in CI you can also use scripts generated in ./Library/coherence folder /project_path/Library/coherence/run-replication-server-rooms.sh and /project_path/Library/coherence/run-replication-server-worlds.sh.
If you want to automate the uploading of schemas, keep in mind that you need to set the COHERENCE_PORTAL_TOKEN environment variable in your continuous integration setup so the upload is accepted by the coherence Cloud. You can get the token from coherence Dashboard > Project > Settings > Project Settings > Project Token.
You can use the Simulator Build Pipeline public API to build and upload your Simulator builds to the coherence Cloud from the command line. If you wish to learn more about Simulators, check out the dedicated section.
There are two methods you will need to call, in order, to build and upload a Simulator build successfully:
Coherence.Build.SimulatorBuildPipeline.PrepareHeadlessBuild This method will add the COHERENCE_SIMULATOR scripting symbol, will set the build sub target to Server (for Unity 2021) and it will change the platform to Linux. It is necessary to perform these steps in an isolated Unity execution, because in batch mode, there is no editor loop that will make sure your assemblies are reloaded with the changes.
Coherence.Build.SimulatorBuildPipeline.BuildHeadlessLinuxClientAsync ****This method will build the Unity Client and upload it to your selected organization and project.
In order to be able to interact with your coherence Dashboard from the command line, you will need to export your project token as an environment variable.
You can create your custom build steps by implementing Unity interfaces IPreprocessBuildWithReport and IPostprocessBuildWithReport. In order to verify that the build being created is a Simulator, you can check for the SimulatorBuildPipeline.IsBuildingSimulator boolean.
Creating massive multiplayer worlds
Unity has a well-known limitation of offering high precision positioning only within a few kilometers from the center of the world. A common technique to get around this limitation is to move the whole world underneath the player. This is called world origin shifting. Here's how you can use it with coherence.
Unity uses 32-bit floating-point numbers to represent the world position of game objects in memory. While this format can represent numbers up to , its precision decreases as the number gets larger. You can use this site to see that already around the distance of meters the precision of a 32-bit float is 1 meter, which means that the position can only be represented in steps of one meter or more. So if your Game Object moves away from the origin by 1000 kilometers it can be only positioned with the accuracy of 1000km and one meter, or at 1000km and two meters, but not in between. As a result, usable virtual worlds can be limited to a range of as little as 5km, depending on how precisely GameObjects need to be tracked.
Having a single floating world origin as used in single player games is not sufficient for multiplayer games since each player can be located in different parts of the virtual world. For that reason, in coherence, all positions on the Replication Server are stored in absolute coordinates, while each Client has its own floating origin position, to which all of their game object positions are relative.
To represent the absolute position of Game Objects on the Replication Server, we use the 64-bit floating-point format. This format allows for sub-1mm precision out to distances of 5 billion kilometers. To keep the implementation simple, floating origin position and any Game Object's absolute position is limited to the 32-bit float range, but because of the Floating Origin, it will have precision of a 64-bit float when networked with other Clients.
Here is a simple example how the floating origin could be used. We will create a script that is attached to the player Prefab and is active only on the Client with authority.
Calling the CoherenceBridge.TranslateFloatingOrigin will shift all CoherenceSync objects by the translated vector, but you have to shift other non-networked objects by yourself. We will create another script which takes care of this.
When your floating origin changes, the CoherenceBridge.OnFloatingOriginShifted event is invoked. It contains arguments such as the last floating origin, the new one, and the delta between them. We use the delta to shift back all non-networked game objects ourselves. Since the floating origin is Vector3 of doubles we need to use ToUnityVector3 method to convert it to Vector3 of floats.
To control what happens to your entities when you change your floating origin, you can use CoherenceSync's floatingOriginMode and floatingOriginParentedMode fields. Both are accessible from the inspector under Advanced Settings.
Available options for both fields are:
MoveWithFloatingOrigin - when you change your floating origin, the Entity is moved with it, so its relative position is the same and absolute position is shifted.
DontMoveWithFloatingOrigin - when you change your floating origin, the Entity is left behind, so its absolute position is the same and relative position is shifted.
Floating Origin Mode dictates what happens to the Entity when it is a Root Object in the scene hierarchy, and Floating Origin Parented Mode dictates what happens to it when its parented under another non-synced Game Object.
If the Entity is parented under another CoherenceSync Object (even using CoherenceNode), its local position will never be changed, since it will always be relative to the parent.
If you are using Cinemachine for your cameras, you'll need to call OnTargetObjectWarped to notify them that the camera target has moved when you shift the floating origin.
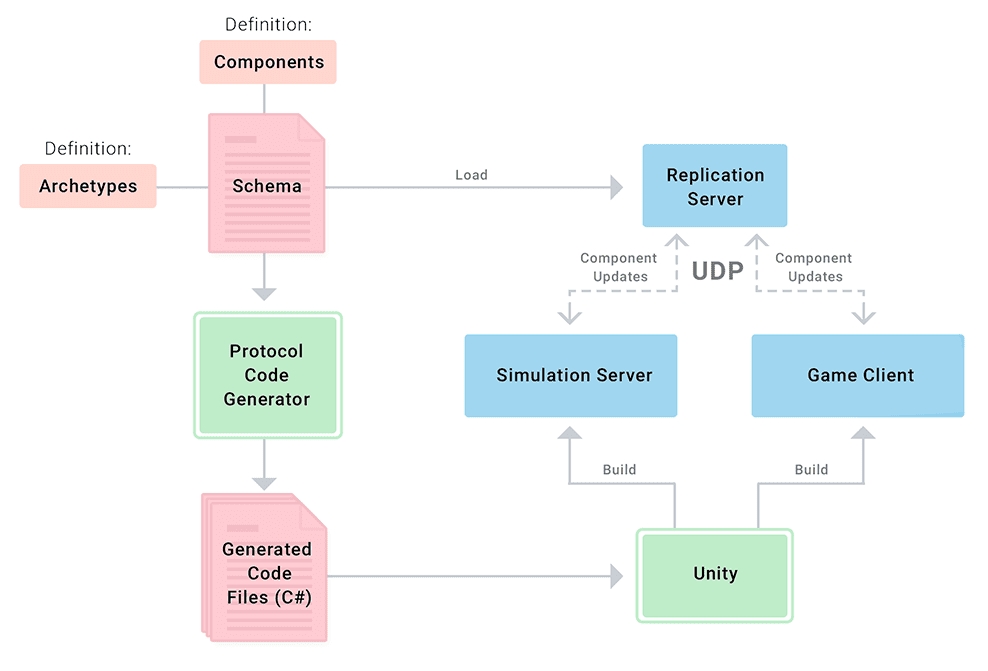
While the schema is a central concept in coherence, most developers won't need to worry about how it works internally, as the coherence SDK automates most of the work involved.
This article is only interesting to those who want to understand more about the internals of how schemas work in coherence.
The schema is a text file defining the structure of the game world from the network's point of view. The schema is shared between the Replication Server, Simulators and Game Clients. The world is generally divided in components and .
In other words, the schema defines what, how much, how fast and how precisely data is being exchanged between clients and the Replication Server.
The schema file has two uses in your project:
As a basis for code generation, creating various structs and methods that can be used in your project to communicate with the Replication Server.
As a description for the Replication Server, telling it how the data in your project looks like – to receive, store, and send this data to its Clients.
When using MonoBehaviours and CoherenceSync you often don't need to interact with the schema directly. Here's an example of a small schema:
If you're unsure where schema files are located, you can easily search through the project using Unity's project search window, witht:Coherence.SchemaAsset
This document explains how Archetypes work internally. If you're looking for how Level of Detail works in coherence with CoherenceSync, see instead.
(or LOD-ing, for short) is a technique to optimize the amount of data being sent from the Replication Server to each Client. Often a Client doesn't need to get as much information about an Entity if it's far away. The way this is achieved when working with coherence is by using Archetypes.
Archetypes let you group components together and create distinct "levels of detail". Each such level must have a distance threshold, and a list of components that should be present at that distance. Optionally it can also contain per-field overrides that make the primitive data types in the components take up less space (at the cost of less precision.)
To define an Archetype, use the archetype keyword in your schema, then list the LODs in ascending order. Notice that LOD 0 does not need a distance, since it always starts at 0. Here's an example of a simple Archetype:
In this example, any Enemy Entity that is 200 or more units away from the LiveQuery of a particular Client will only get updates for the WorldPosition. Any client with a distance of 10 – 200 will get WorldPosition and WorldOrientation, and anything closer than that will get the full Entity.
Given one or more Archetype definitions in your schema, you will have access to a few different data types and methods in your project (these will be generated when you run the Protocol Code Generator.)
ArchetypeComponent – this component has a field index that keeps track of which one of the Archetypes in your schema that is being used. If you add the ArchetypeComponent yourself you have to use the static constants in the Coherence.Generated.Archetype to set the index. These all have the name "Archetype name" + "Index", e.g. EnemyIndex in the example above.
An individual "tag" component (with no fields) called "Archetype name" + "Archetype", e.g. EnemyArchetype in the example above. This component can be used to create optimized ForEach queries for a specific Archetype.
LastObservedLod – this component holds the current LOD for the Entity. This can be used to detect when the Entity changes LOD, if that's something you want to react to. Note that this component is not networked, since the exact LOD for an Entity is unique for each Client.
Static helper methods on the Archetype class to instantiate the Archetype in a usable state. These are named "Instantiate" + "Archetype name", e.g. InstantiateEnemy in the example above.
If a component isn't present at a certain LOD, no updates will be sent for that component. This is a great optimization, but sometimes a little too extreme. We might actually need the information, but be OK with a slightly less fine-grained version of it.
To achieve this, you can use the same field settings that are available when defining components, but use them as overrides on specific LOD's instead.
Here's an example of the syntax to use:
Notice that the settings are exactly the same as when defining components. To override a field, you must know its name (value in this case.) Any field that is not overridden will use the settings of the LOD above, or the original component if at LOD 0.
Each component in an Archetype can also override the default priority for that component. Just add the priority meta data after the component, like this:
Many of the primitive data types in coherence support configuration to make it possible to optimize the data being sent over the network. These settings can be made individually for each field of a component and will then be used throughout your code base.
The field settings uses the meta data syntax in the schema, which looks like this:
The meta data always goes at the end of the line and can be set on both definitions and the fields within a definition, like this:
In this example, a component named Health would be created, but instead of using the default 24 bits when sending its value, it would just use 8. Any updates to it would also be deprioritized compared to other components, so it could potentially be sent a bit late if bandwidth is scarce.
Component updates do not only contain the actual data of the update, but also information about what Entity should be affected, etc. This means that the total saving of data won't be quite as large as you'd think when going from 24 to 8 bits. Still, it's a great improvement!
All components support a piece of meta data that affects how highly the Replication Server will prioritize sending out updates for that particular component.
This meta data is set on components, like this:
The available priority levels are:
"very-low"
"low"
"mid" (default)
"high"
"very-high"
Some of the primitive types support optimizing the number of bits used to encode them when sending the over the network. It's worthwhile to think through if you can get away with less information than the default, to make room for more frequent updates.
All of these types support the same two settings:
compression - type of compression used
None - no compression - full float will be sent
FixedPoint - user specified value range is divided equally using a defined precision. Requires range-min, range-max, bits and precision meta data.
Truncated - floating point precision bits are truncated, resulting in a precision loss, however with a full float value range available
bits – how many bits the type should use to encode its floating point values. Usable only with FixedPoint and Truncated compressions
precision – how much precision will be guaranteed. Usable only with FixedPoint compression. Strictly related to bits and shouldn't be set manually
Integers can be configured to only hold a certain range via:
range-min – the lowest possible value that the integer can hold
range-max – the largets possible value that the integer can hold
Using these settings you can emulate other numeric types like char, short, unsigned int, etc.
Quaternions can have a number of bits per component specified using the bits meta data. Serialization requires writing 3 components and an additional sign bit, thus the total amount of bits used for quaterion is bits * 3 + 1.
Quaternions can have a number of bits per component specified using the bits meta data. Serialization requires writing 4 components (RGBA), thus the total amount of bits used for color is bits * 4.
The other types don't have any settings that affect the number of bits they use. If they take up too much bandwidth you'll have to try to send them less often, using priority, update frequency, or LODing.
Unity supports as part of the engine. Code stripping means automatically removing unused or unreachable code during the Unity build process to try and significantly decrease your application’s final size.
Setting Code Stripping above Minimal level is risky and might break your game by removing code that's needed for it to run.
If you're considering using code stripping above Low level, add the following link.xml file anywhere in your project (we recommend Assets/coherence/link.xml):
Read more on how link.xml works in Unity on their section.
In any case, there's no one-size-fits-all solution to be safe when it comes to code stripping. It highly depends on your project, and also your dependencies (third party libraries and assets used).
If you are experiencing issues with coherence while using code stripping,.
__
Several of the primitive types can be configured to take up less space when sent over the network, see .
Archetypes are used to optimize the sending of data from the Server to each Client, lowering the precision or even turning off whole components based on the distance from the LiveQuery to a particular Entity. Read more about how to define them in the schema on the page .
When using reflection, there are limitations to what types are supported in commands. See the section for more information.
To learn more about the types and definitions available in a schema, see the .
To read more about priority, see the page about .
How coherence behaves when a Client is not connected
Even though coherence is a networking solution, there might be instances when a Scene configured for online play is used offline, without connecting to a Replication Server. This can be useful for creating gameplay that works in an offline game mode (like a tutorial), or simply a game that can connect and disconnect seamlessly during uninterrupted gameplay.
The ability to create Prefabs and code that can be used both online and offline is an great tool that in the long term can streamline the development process, avoid duplicated code, ultimately creating less bugs.
To ensure that the code you write doesn't break when offline, follow these recommendations:
Check if a CoherenceBridge is connected using CoherenceBridge.isConnected.
CoherenceSync components also have a reference to the associated bridge, so if one is present in the Scene you can use sync.CoherenceBridge.isConnected for convenience.
When offline, CoherenceSync.EntityState is null. Use this to your advantage to identify the state of the connection.
Authority is assumed on offline entities (CoherenceSync.HasStateAuthority always returns true).
You can use commands. They will be routed to local method calls.
When offline, some events on coherence components (e.g., CoherenceBridge.OnLiveQuerySynced) won't be fired, so review any game logic that depends on them.
Persistence and uniqueness are not resolved when offline, so don't make assumptions about their network state.
When offline, if you have a Prefab in the Scene that is set to Simulate In Server Side, it won't be automatically removed (since there's no connection, hence coherence can't infer if it's a Simulator or a Client connection). You can use SimulatorUtility.IsSimulator in an OnEnable() and deactivate it.
In case of a server-authoritative scenario using CoherenceInput, you might want to isolate state-changing code that would run in the Simulator into its own script. This way, it can be reused to directly affect the state of the entity when the game is offline.
See below for a more in-depth description of how the different components behave.
This section describes how the different components offered by coherence behave when the game is offline.
Because the CoherenceBridge never tries to connect, it won't fire any connection-related events.
You won't be able to query the list of ClientConnections, and all Room or World related data or Services data won't be there.
However, you will be able to access through the CoherenceBridge what is part of the setup at edit time. For instance, you will be able to inspect the list of CoherenceSyncConfig objects in order to instantiate connected Prefabs.
Connected Prefabs that feature a CoherenceSync can be instantiate and destroyed like usual while offline.
Because it's always the local Client that creates instances of connected Prefabs, it will automatically receive full authority on all of them. Consequently, the OnStateAuthority callback will be invoked when the object is instantiated, in OnEnable(). Check on sync.HasStateAuthority will return true, as early as Awake().
The Client has authority to manipulate its state, and can destroy the Prefab instance at will.
If a Component has been configured to be enabled/disabled as a result of authority changes (that is, using Component Actions), it will be enabled.
No change in behavior. Network Commands will invoke the corresponding method with a direct invocation, with no network delay incurred.
Prefabs marked as Persistent will not persist after an offline game session. They will be destroyed when the Scene they belong to is unloaded, and will not be automatically recreated if the Scene is re-loaded.
Persistence is tied to the World or Room the Client is connected to. If you need objects to persist between different offline sessions, you need to store their state some other way.
Like persistence, uniqueness is also verified within the context of the Room or World the Client is connected to, and is generally used for ensuring that a different Client can't bring an already existing entity to the simulation.
When offline, no check happens for uniqueness, meaning that unique entities can be instantiated multiple times. It is therefore up to the local gameplay code to make sure this doesn't happen in the first place.
Any Prefab for which the property Simulate In has been set to Server-Side will not be automatically deactivated on instantiation.
To ensure such a Prefab doesn't appear in an offline session, make sure to deactivate it in its code by using:
LiveQuery components will not have any effect offline. However, keep in mind that they will try to find the CoherenceBridge, so if none is present they will throw an error. For this reason it's a good idea to keep them together, and only have a LiveQuery in the scene if a CoherenceBridge is present.
Any CoherenceNode component will have no effect. There are no drawbacks for leaving it inside the Prefabs.
Given that it's inherently meant to be used in a Client-Server scenario, CoherenceInput has no meaning offline.
However, you can safely leave the component on your Prefabs, and architect your scripts so that rather than sending inputs to CoherenceInput regardless, they first check if the Client is connected and, in case of a negative answer, manipulate the entity's state instead.
It can be a good idea to isolate the code used to manipulate the entity's state during prediction, and reuse it for offline behavior.
If the game is online, input is sent to the Simulator via CoherenceInput, while at the same time prediction is done locally and applied. On the Simulator, the same code used from the Client to do prediction is used to compute the final state. Once an update is received, reconciliation code kicks in and corrects any mismatches.
In offline mode, the same code used for the prediction is used for driving the entity's state instead, and no input is forwarded to CoherenceInput.