Many of the primitive data types in coherence support configuration to make it possible to optimize the data being sent over the network. These settings can be made individually for each field of a component and will then be used throughout your code base.
The field settings uses the meta data syntax in the schema, which looks like this:
The meta data always goes at the end of the line and can be set on both definitions and the fields within a definition, like this:
In this example, a component named Health would be created, but instead of using the default 24 bits when sending its value, it would just use 8. Any updates to it would also be deprioritized compared to other components, so it could potentially be sent a bit late if bandwidth is scarce.
Component updates do not only contain the actual data of the update, but also information about what Entity should be affected, etc. This means that the total saving of data won't be quite as large as you'd think when going from 24 to 8 bits. Still, it's a great improvement!
All components support a piece of meta data that affects how highly the Replication Server will prioritize sending out updates for that particular component.
This meta data is set on components, like this:
The available priority levels are:
"very-low"
"low"
"mid" (default)
"high"
"very-high"
Some of the primitive types support optimizing the number of bits used to encode them when sending the over the network. It's worthwhile to think through if you can get away with less information than the default, to make room for more frequent updates.
All of these types support the same two settings:
compression - type of compression used
None - no compression - full float will be sent
FixedPoint - user specified value range is divided equally using a defined precision. Requires range-min, range-max, bits and precision meta data.
Truncated - floating point precision bits are truncated, resulting in a precision loss, however with a full float value range available
bits – how many bits the type should use to encode its floating point values. Usable only with FixedPoint and Truncated compressions
precision – how much precision will be guaranteed. Usable only with FixedPoint compression. Strictly related to bits and shouldn't be set manually
Integers can be configured to only hold a certain range via:
range-min – the lowest possible value that the integer can hold
range-max – the largets possible value that the integer can hold
Using these settings you can emulate other numeric types like char, short, unsigned int, etc.
Quaternions can have a number of bits per component specified using the bits meta data. Serialization requires writing 3 components and an additional sign bit, thus the total amount of bits used for quaterion is bits * 3 + 1.
Quaternions can have a number of bits per component specified using the bits meta data. Serialization requires writing 4 components (RGBA), thus the total amount of bits used for color is bits * 4.
The other types don't have any settings that affect the number of bits they use. If they take up too much bandwidth you'll have to try to send them less often, using priority, update frequency, or LODing.
This document explains how Archetypes work internally. If you're looking for how Level of Detail works in coherence with CoherenceSync, see this page instead.
Level of Detail (or LOD-ing, for short) is a technique to optimize the amount of data being sent from the Replication Server to each Client. Often a Client doesn't need to get as much information about an Entity if it's far away. The way this is achieved when working with coherence is by using Archetypes.
Archetypes let you group components together and create distinct "levels of detail". Each such level must have a distance threshold, and a list of components that should be present at that distance. Optionally it can also contain per-field overrides that make the primitive data types in the components take up less space (at the cost of less precision.)
To define an Archetype, use the archetype keyword in your schema, then list the LODs in ascending order. Notice that LOD 0 does not need a distance, since it always starts at 0. Here's an example of a simple Archetype:
In this example, any Enemy Entity that is 200 or more units away from the LiveQuery of a particular Client will only get updates for the WorldPosition. Any client with a distance of 10 – 200 will get WorldPosition and WorldOrientation, and anything closer than that will get the full Entity.
Given one or more Archetype definitions in your schema, you will have access to a few different data types and methods in your project (these will be generated when you run the Protocol Code Generator.)
ArchetypeComponent – this component has a field index that keeps track of which one of the Archetypes in your schema that is being used. If you add the ArchetypeComponent yourself you have to use the static constants in the Coherence.Generated.Archetype to set the index. These all have the name "Archetype name" + "Index", e.g. EnemyIndex in the example above.
An individual "tag" component (with no fields) called "Archetype name" + "Archetype", e.g. EnemyArchetype in the example above. This component can be used to create optimized ForEach queries for a specific Archetype.
LastObservedLod – this component holds the current LOD for the Entity. This can be used to detect when the Entity changes LOD, if that's something you want to react to. Note that this component is not networked, since the exact LOD for an Entity is unique for each Client.
Static helper methods on the Archetype class to instantiate the Archetype in a usable state. These are named "Instantiate" + "Archetype name", e.g. InstantiateEnemy in the example above.
If a component isn't present at a certain LOD, no updates will be sent for that component. This is a great optimization, but sometimes a little too extreme. We might actually need the information, but be OK with a slightly less fine-grained version of it.
To achieve this, you can use the same field settings that are available when defining components, but use them as overrides on specific LOD's instead.
Here's an example of the syntax to use:
Notice that the settings are exactly the same as when defining components. To override a field, you must know its name (value in this case.) Any field that is not overridden will use the settings of the LOD above, or the original component if at LOD 0.
Each component in an Archetype can also override the default priority for that component. Just add the priority meta data after the component, like this:
To read more about priority, see the page about Field settings.
These are the primitive types supported in a coherence schema:
Uses a default range of -2147483648 to 2147483647 (32 bits).
Uses the default range of 0 to 4294967295 (32 bits).
Uses the default range of -9223372036854775808 to 9223372036854775807 (64 bits).
Uses the default range of 0 to 18446744073709551615 (64 bits).
Encoded using one of the following compression types: None, Truncated, FixedPoint (defaults to None).
Higher precision floating point using 64 bits. It does not support compression.
Encoded using a single bit.
Encoded using two floats with a specified compression (defaults to None).
Encoded using three floats with a specified compression (defaults to None).
Encoded using three components and a sign bit.
Encoded using four components (RGBA).
A string with up to 63 bytes encoded using 6 bits for length.
An array of bytes with an upper limit of 511 bytes encoded using 9 bits for length.
Packet fragmentation is not supported yet in this version, so packets bigger than the internal MTU (~1200 bytes) may be never sent.
The Entity type is used to keep references to other Entities. Technically the reference is stored as a local index that has to be resolved to an actual Entity before usage. Also, since a Client might not know about the referenced Entity (due to it being outside of its LiveQuery) an Entity reference might be impossible to resolve in some circumstances. Your Client code will have to take this into account and be programmed in a defensive way that handles missing Entities gracefully.
Several of the primitive types can be configured to take up less space when sent over the network, see Field settings.
The most common definition in schemas is components, which correspond to replicated fields for baked MonoBehaviours.
The definition takes a name of the component, and on the following lines an indented list of member variables, each one followed by their primitive type (see above.) The indentation has to be exactly 2 spaces. Here's how it might look:
After code generation, this will give access to a component with the name Portal that has the members locked, connectedTo, and size.
Optionally, each member/type pair can have additional meta data listed on the same line, using the following syntax:
This is how it might look in an actual example:
There are some components that are built into the Protocol Code Generator and that you will always have access to.
Archetypes are used to optimize the sending of data from the Server to each Client, lowering the precision or even turning off whole components based on the distance from the LiveQuery to a particular Entity. Read more about how to define them in the schema on the page Archetypes and LOD-ing.
Commands are defined very similarly to components, but they use the command keyword instead.
Here's a simple example of a command:
Routing defines to whom the command can be sent. Currently, two values are supported:
AuthorityOnly - command will be received only by the owner of the target Entity
All - command will be received by every Client that has a copy of this Entity
When using reflection, there are limitations to what types are supported in commands. See the Supported types in commands section for more information.
Inputs represent a group of values that are snapshotted every frame (or fixed frame). This snapshot is then sent to other clients or a session host, so it can be processed by the same code on both ends, resulting in the same outcome.
Example of an input:
Schemas have limits to protect the Replication Server. Ensure you stay within these limits:
A single schema cannot have more than 10 million characters
A component/command name cannot be more than 512 characters
A field/archetype/input/enum name cannot be longer than 128 characters
A component cannot have more than 128 fields
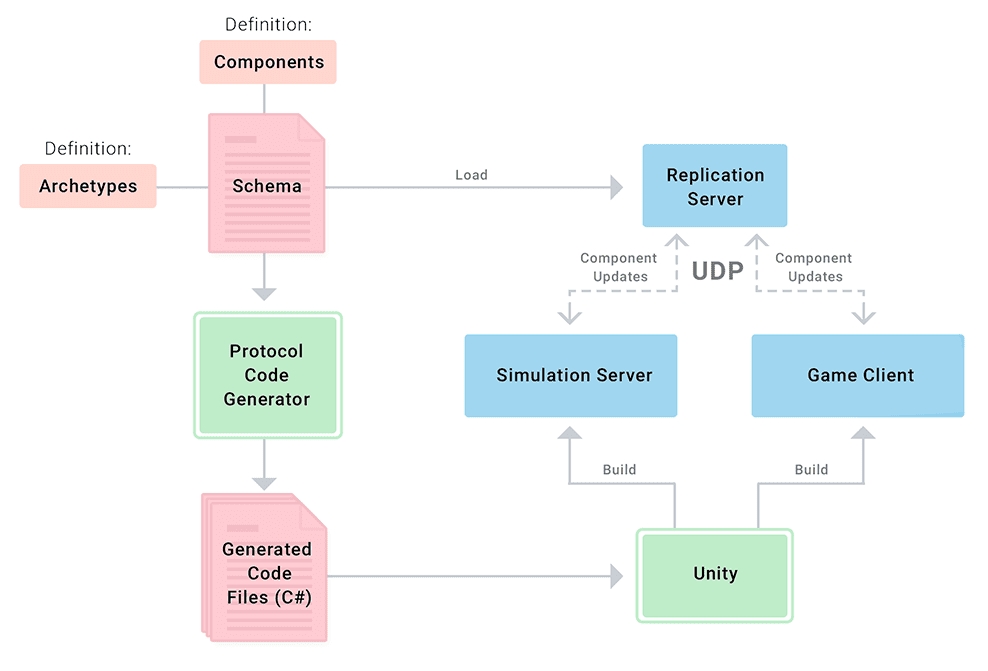
While the schema is a central concept in coherence, most developers won't need to worry about how it works internally, as the coherence SDK automates most of the work involved.
This article is only interesting to those who want to understand more about the internals of how schemas work in coherence.
The schema is a text file defining the structure of the game world from the network's point of view. The schema is shared between the Replication Server, Simulators and Game Clients. The world is generally divided in components and archetypes.
In other words, the schema defines what, how much, how fast and how precisely data is being exchanged between clients and the Replication Server.
The schema file has two uses in your project:
As a basis for code generation, creating various structs and methods that can be used in your project to communicate with the Replication Server.
As a description for the Replication Server, telling it how the data in your project looks like – to receive, store, and send this data to its Clients.
When using MonoBehaviours and CoherenceSync you often don't need to interact with the schema directly. Here's an example of a small schema:
To learn more about the types and definitions available in a schema, see the specification.
If you're unsure where schema files are located, you can easily search through the project using Unity's project search window, witht:Coherence.SchemaAsset